
Download the slides for this talk (PDF, 325k).
As I write this, Inform 7 is approaching its third birthday. I7 is a tool for creating interactive fiction (text adventure games). Like all the most powerful IF development tools, I7 is a programming language -- a powerful and peculiar one.

Inform 7 gets a lot of attention for its English-like syntax. I'm not going to talk about the natural-language aspects of I7. I'm going to talk about the underlying programming model, the system of rules and rulebooks. That's less attention-grabbing than the flashy syntax; but, in my opinion, it's equally radical. And perhaps a more important development, in the long run.
To be fair, I also like talking about the rule-based programming model because I contributed some of its ideas, back when I7 was first taking shape. I'm not claiming authorship here, mind you. I got into a long and digressive email conversation with Graham Nelson and Emily Short, in which we all threw ideas around, and then Graham went ahead and spent six years developing his ideas. I shoved mine on the shelf.
This means that I will talk about I7 for a while, and then break into a wild flight of "but this is how I think it should be done!" And then finish up with all the reasons I haven't made it work yet. Such is a hacker's life.
The rule-based programming model is not new. It's got connections to logical programming languages, as in Prolog. It's related to (or maybe the same as) aspect-oriented programming. But why do I like this model? Well, why does anybody like any kind of programming model?
A programming language is a tool for handling design complexity. That's what all of computer science is, really -- languages, libraries, type systems, garbage collectors, everything you learn about programming. They're ways to build more and more complex designs without losing your grip.
The way you manage complexity is to be able to ignore it. A good programming tool lets you forget about some part of the problem, so that you can focus on some other part. And it ensures that when you return to the parts you forgot, you haven't accidentally broken them.

The first work of IF, Adventure, was a messy FORTRAN hack. The second, Dungeon (or Zork), was created at MIT, so it was a messy LISP hack. (Actually a LISP dialect called MDL, which is why you see angle brackets as well as parentheses.)
These were messy because they were built as games, not game-design tools. The creators were figuring out how to build IF worlds on the fly.
The MIT gang went on to create the first well-known IF design system, under the Infocom banner. It consisted of a virtual machine, a language called ZIL, a compiler for the language, and a parser library written in the language. ZIL looked a lot like MDL, but it actually had a much simpler structure; it was essentially BASIC written with parentheses. (I mean angle brackets.)

Adventure and Dungeon sparked lots of imitators. The next twenty years gave us a whole roster of IF development systems. These were mostly created by people who had learned to program in the 70s and 80s, so the languages followed the programming models you'd expect: BASIC-like, C-like, Pascal-like. Although, to be fair, a couple were genuinely LISP-y.
How did these systems compare? Small code samples, like the ones above, show off difference in syntax. But the underlying code model is important too. For example, the version of Adventure I quoted was written almost completely without functions. (Just two small utility functions are used.) The parser and game logic are all one mass of loops and gotos. Nobody would consider writing a complex program that way today.
So, the simplest IF systems had if/else statements. The more advanced ones had functions and data structures. The most complex aspired to what people thought of as the sacred peak of computer science: object-oriented programming.
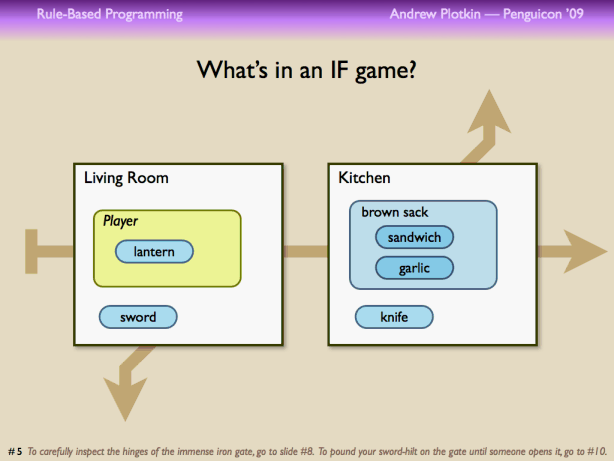
It's not hard to imagine why designers moved towards OO design tools. Think about what a typical IF game comprises. You've got some rooms, which contains objects. Some objects are containers, so they have other objects inside them. And then you have some representation of the player, which can also contain objects.
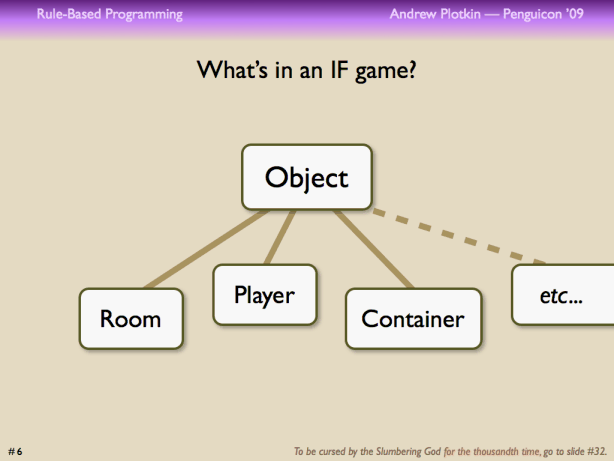
Everybody likes to generalize, and the obvious generalization is to say that a container is a kind of object. Then the player looks like a special object, and rooms can be objects too (or maybe a special kind of container). Presto, everything in the world is an object. Maybe object-oriented programming would be a good fit!

Here's a common OO pattern: an object field (or property). Every object in the game has a description, its response to the "EXAMINE" command. A field works nicely for that. We can define a description field in the base class, of type string. This basic description applies to all objects, as a default; we can then override it for specific objects.
This is working really well! It gets a little trickier, though, because many objects have dynamic descriptions. They change over the course of the game. For example, the bottle can be filled with either water or oil.
We could handle this by assigning a new value to Bottle.description every time the bottle changed state. Sometimes that's practical. But we'd like a more flexible option; we'd like to associate some code with the bottle which computes the current description.

Code associated with an object is, of course, an object method. Here's the object description implemented as a method instead of a string field.
By the way, this model leaves us with a lot of one-line print methods. Many descriptions aren't dynamic. So it winds up being convenient to allow a shortcut, where you say "description: STRING" and interpret that as a method that prints STRING. Inform 6 has this shortcut, for example. But it's syntactic sugar; it doesn't change the model.
I've used a more interesting shortcut here. Some OO languages, like Java, are very strict about the distinction between objects and classes. You define classes, and then instantiate them to create objects.
That's a nuisance in IF, because most objects in an IF game are unique. Adventure only has one glass bottle. It would be tedious to have to define a Bottle class and then do Bottle.new(). So OO IF languages tend to use a prototyping model: you can define a one-off object with its own fields and methods, and then maybe subclass it if you need to. That's what I've done above.
Descriptions are a bit of a special case. The basic behavior of an IF game is a read-parse-perform loop: read a command from the player, parse it into action data, and then execute the action. How does that look in an OO system?
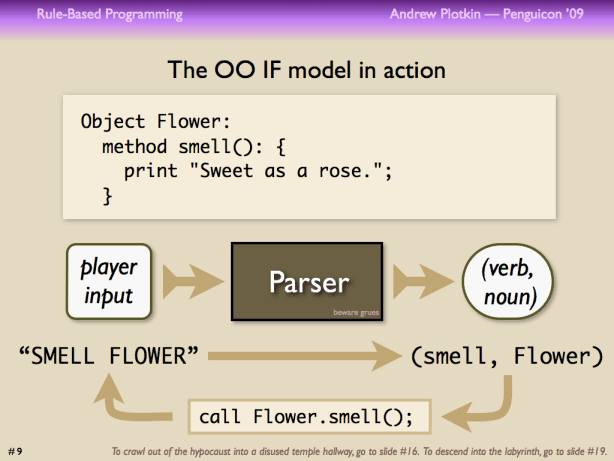
Let the parser be a black box. (A black box with months of fiddly work inside it, sure.) It sucks in the player's command, and spits out a tuple (VERB, NOUN). OO doctrine says that a VERB is a method, and a NOUN is an object. So we call that method of that object. End of turn, read the next command.
So we define a bunch of objects, give them appropriate action methods, drop the parser on top, and we've got a game, right? Right... until we try to do anything more complicated. Then it falls apart like a bundle of ball bearings.

When it's dark, you can't examine anything; or rather, you always get the same response: "It's too dark to do that." But where do we put that check? It applies to all objects, but if we put it in the Object.examine() method, any specific object method will short-circuit it. We could paste the same check into Sword.examine(), Lamp.examine(), ... every object in the game... but that's the kind of repetitive coding style that OO was supposed to fix.
What about the "LOOK" command? That doesn't have an object at all, which is a little problematic for object-oriented code. Maybe single-verb commands should be routed to the room. That makes sense for "LOOK", but not so much for "INVENTORY".
"PUT MEAT IN BASKET" is even worse -- it has two objects, a direct object and an indirect object. We could invoke a method on the Meat object or the Basket object. Really, we'd want to invoke methods on both, because either one could customize the default "PUT X IN Y" action. (A thimble is too small to put most objects in; smoke is too diffuse to be put into anything.)
The method we're writing might belong on some other object entirely. Imagine a room with an orc and a pie. If you try to take the pie, the orc kills you, unless you've killed him first or otherwise removed him from the room. It would be logical to send the orc object a message for every "TAKE" action in the room. Where does this stop? Should we invoke a method on every object in the room for every action? (In what order?)
Another fun case: some checks apply to multiple actions. An electrified lever zaps you if you pull, push, or even touch it. We don't want to copy that check into every touching method. Maybe we could have "pull" and "push" be subclasses of a base "touch" class... except, hang on, that makes no sense. OO has no notion of methods subclassing other methods.
I suppose we could drop the "verbs are methods" scheme, and represent verbs as abstract objects. Pass the verb as a parameter. Instead of invoking Flower.smell(), we'd invoke Flower.do(Smell). But we also need those multi-object checks, so we'll pass the object as a parameter too: Player.do(Smell, Flower).

This neatly covers all the cases I've described. It's perfect. Except -- now all of our game logic is jammed into one enormous method, full of if and switch statements. Perfect, if your goal is to go stark staring bonkers.

This is how Inform 6 manages its code. Every action invokes this wrapper function, which invokes a whole slew of object methods: on the player, on nearby objects, on the room itself, on the command target object. Each of these in turn has its chance to determine the action outcome. If none of them raise a hand, the action's default behavior is invoked.
This is usable. I've written complex games in Inform 6. But you can't call it "object-oriented" in any deep sense. It's the stilted result of deciding that every bit of code must be associated with one object, and then trying to name (in advance) every object that some action code might be associated with. It gets the job done, as long as you're willing to force yourself into its mold.
(Even when you do, it's not as flexible as you might hope. For example, the order of method checks is rigid. You can't write a room effect that overrides a nearby-object effect.)
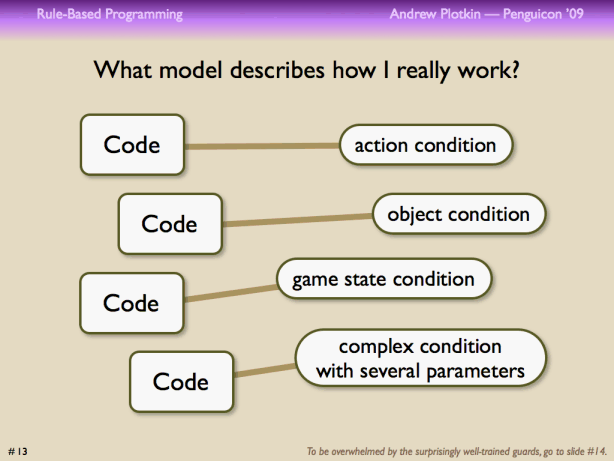
So I sat back and said to myself, player, how am I really using Inform 6? I'm not looking at objects and then deciding what methods to override. Rather, I'm thinking up conditions, and then working out what objects and methods I6 wants me to attach them to. I feel like I'm designing my game and then porting it to I6.
The question, then, is what language am I porting it to I6 from?
If I were working in a language that fit my approach, I would create a cloud of rules and conditions. The compiler would then knit them together into a game. Some of my rules would be associated with objects, as in I6. But other rules would be associated with actions, and others with global game state (like the time of day). It's the compiler's job to ensure that every relevant rule is considered in the course of handling an action.

Here's a pass at what a rule might look like, as a program element.
The atom identifies what process we're carrying out or computing. The behavior of an atom is defined by one or several rules. (The atom might have parameters, but we'll get to that in a moment.)
The code is arbitrary code; it does something. (Let's take for granted the shortcut I mentioned above, where a bare string means "print this string".)
The condition describes under what circumstances this code should be used for the atom.

This is less alien than it sounds. If we strip off the condition part of the rule, what we're left with is -- an ordinary function. "To do FuncName, run this code." The condition is effectively "always"; you can read it as an implied "...if true" condition.

If we throw in an object parameter, we can effectively build an object field. The first rule, with an "if true", defines the general condition -- it always holds, unless another rule overrides it. The second rule applies to a class of objects. The third rule applies to a specific object.
Of course we need the compiler to understand that the second rule overrides the first rule, and the third overrides the second. That's doable, at least in theory. The first condition is clearly totally generic. And if we've defined the Hope Diamond as being a treasure, then the compiler can tell that the third condition is a specific case of the second. So these logical relationships will get all the rules lined up in the right order -- at least for this simple case.

By the way, we don't really need the atom part of the rule at all. We could treat the atom as just another parameter. That simplifies the syntax, at the cost of making the conditions more complicated.
Maybe this is the theoretically pure path. It's certainly more powerful -- it lets us define rules that cover several different atoms. But it's one step farther than I'm willing to go. I need some irreducible structure to hang my scarf on, and atoms are it. (That's why I call them "atoms". In Inform 7, they're called "rulebooks".)

We can set up many familiar programming structures using this rule mechanism. For example, a constant is just a one-rule atom with no parameters, which returns a value. (Again, we might want to write simple actions as bare values.)

An object method works just like an object property -- a list of rules based on class membership.

What about a property whose value can be reassigned? Computed property values are nice, but sometimes you really do want to store a new value somewhere. Here we have a delicate vase which is rendered worthless if you hit it.
(I'm sneaking another syntactic shortcut in on you. The condition of this rule is really "...if (obj is MingVase)". I've just specified the parameter condition directly.)
The assignment operator, :=, needs to fit into the rule system. Let's treat it as this implicit, overriding rule:

The compiler will have to generate these implicit rules for any atoms that are assigned to in the program code. It will also have to keep track of what values have been assigned where. No big deal; it's just a lookup table, managed behind the scenes.

This sort of assignment rule works just as well for simple global variables. Here's a Score atom which starts out as zero, but increases at a particular point in the game.
Note that the first rule defines a constant, same as we defined Pi earlier. Then the second rule turns the constant into a variable. Don't let this scare you. Plenty of programming languages let you rebind any identifier at any time.
Let's get a bit more ambitious. I've been writing rule conditions that use the "ofclass" operator, as if I had a traditional object hierarchy to work with. Pretend I don't like traditional object hierarchies, and want to use atoms instead.

A class is just a set of objects; we can implement that as a membership property. Three very simple rules. All objects are non-treasures, with these two exceptions. Now we can rewrite the earlier Price rules without any need for the "ofclass" operator.
When you get down to it, an inherited property value is just one property (the Price) derived from another (the Treasure membership property). So we have one atom whose computation depends on another atom.
The compiler will have to track this dependency in order to generate appropriate code. But that will be a pretty simple job -- especially since the Treasure rules are so simple. You could imagine more complex dependencies; perhaps a subclass relationship, where one "class" atom implies another. It'll work the same way. We know how to build dependency graphs, and detect circular dependencies, and that's all we need.
Since all atoms play by the same rules, we can do some tricks that traditional OO can't. We can change an object's class, or classes, at runtime. Assign false to Treasure(MingVase), and the vase stops being a treasure. Or we could make Treasure(MingVase) be a more complex computation, derived from other game state, rather than a constant true or false.

Now that I've gotten all of these program structures built, it's time for you all to raise your hands -- good -- and ask me: why? Why am I interested in replacing functions, and classes, and variables and constants, with these rule-based substitutes?
This isn't the path that Inform 7 went down. I7 uses rules for a lot of its infrastructure, but it still has variables and constants and classes and properties. Traditional ones, not made out of rule-stuff. I7's rulebooks aren't very atomic, for that matter. They're fairly heavyweight structures, which take some effort to set up and invoke. You wouldn't want to define a single I7 constant using a rule.
But I think that a rule-based model is appropriate for IF. For big heavy features, for tiny little low-level features, for everything.

The reason, the big overarching reason, is that IF programming is full of exceptions. I don't mean the catch/throw kind of exceptions; I mean exceptional cases. And they're not the kind that you plan for in advance. They're irregular, unpredictable, ad-hoc kinds of exceptions.
Each time you stumble over one of these cases, you write some code that tweaks an existing part of the game logic -- modifying either some library code, or some code you wrote last week. So you can't afford to think about the interactions between this tweak and every other tweak in the game. That's N-squared interactions as your game grows -- too much complexity to handle. You have to be able to ignore them. You have to say, this change applies under these conditions, and all of those changes apply under different conditions, so they're all safe from each other.
I've already talked about the ability to slip from a simple value, perhaps a string, to a dynamic piece of code. You don't want to have to go back and turn a static print statement into a function call, or a function call into a method, just because you changed your mind about how one case should work. The simplest mechanism in the design system should scale up to as much complexity as you need.
IF work usually starts by loading up a standard library. This is a big swathe of pre-built command logic and world logic; you need it, but you need to be able to modify it, too. You need to be able to customize all of it. Really, the characteristic Frustrating Moment of building a text adventure is looking at some part of the library -- a string value, a behavior, a command -- and saying "How do I change that?" (If you're unlucky, it's "Dammit, there's no way to change that.")
An example, so that you don't think I'm making this stuff up. I was working on a game a couple of years ago, and it had a lot of doors. In Inform, a door can be open or closed. That's a boolean property -- you can set it one way or the other. Well, I need one door whose open-ness was a function of the open-ness of several other doors. So now it's a boolean property which, in one case, is a function call.
IF design runs into this all the time. You give the player a numeric score, and then decide that in chapter ten the player will go crazy and his score will be a random number. Or "rhinoceros". Treasures break and become worthless. A telephone needs the attributes of a person, because the "talk" verb is associated with people, and you have to be able to talk to a telephone. (This was a real I7 bug report.)
Earlier I was making fun of the notion of redefining Pi. But redefining string constants is the most elementary level of IF work. The standard library has an message "You are empty-handed"; you want to change that to a more distinctive "You ain't got nothin'." That kind of change should be supported up-front. (It's a non-trivial amount of work in I7, unfortunately.)
It's not just you and the library. Any well-used IF system will have a large collection of third-party libraries, or library extensions. They also want to modify the standard library. At the same time, you are modifying them. There are code tweaks flying back and forth between all these different code sources. Inevitably, some of them will collide. So you need a system which is built from the ground up to resolve separately-defined behaviors.
For that matter, once your game gets beyond a certain point, you're effectively collaborating with yourself. You get chapter one working; then you're working on chapter two, and all that chapter-one code is effectively a library. It does its job, but you may have to make changes that intersect it. You can't annoy the guy who wrote it -- who happens to be you.
One of the dirty open secrets of IF design is that testing is really, really hard. There's no such thing as a complete unit test, because the range of possible input is unbounded. You can go through a scene and tune every verb the player might think of -- and I do -- but it's still not safe, because tomorrow you're going to write more code that involves those verbs and those objects. So, again, you need a development system which is smart at the level of "When does this code apply?"
I am confident that my rule model provides all the flexibility and customizability that I need. The question is, does it provide the safety -- the ability to tune out complexity and focus on one rule at a time, without breaking the whole system. Does this model let you manage complexity, or just bury yourself in it?
Answer: beats the heck out of me.
The tricky bit, and the bit I've been glossing over in this whole rule discussion, is how you handle conflicting rules in a rulebook (that is, an atom).

I mentioned one strategy already: logical precedence. A general rule is always overridden by a more specific rule. For example, if you have a rule for containers, and then a rule for closed containers, the latter is clearly an exception to the former. (Formally: if condition X logically implies condition Y, then rule X overrides rule Y.)
This is great as far as it goes... which is the easy cases. Most rule conflicts are partial overlaps, not clean exceptions. For example, you have a rule for describing living people, and then a rule for describing things when it's dark. Those are two independent conditions. We intuitively feel that the darkness rule takes precedence -- when it's dark, you can't see anything at all. But how does the compiler decide?
All of the easy solutions are terrible. For example, the compiler could decide that if two rules conflict, the earlier one (in the source code) is overridden by the later one. This sucks because one day you reorganize your program, to tidy it up a little, and everything starts working differently. Not good.
Inform 7 has a painfully detailed schema for deciding which rules come before which. It's in the manual, and nobody understands it. (The logical precedence strategy is in there, but in a strange scattered way that I don't understand.) I hate when fundamental language mechanisms are too complicated to understand.
A simple strategy is "don't cope with it." Throw an error and let the author fix it. Fixing it means either declaring which rule takes precedence, or, equivalently, writing a new rule to cover the overlap.

But of course that's the worst possible plan for complexity management. One new broadly-stated rule might conflict with dozens of existing rules, and there's no way the author wants to resolve all those conflicts manually.
Equally of course, the author will have to get involved at some point. The compiler will never be smart enough to resolve every problem on its own. So let's presume the compiler has done its best, and thrown an error. The author is faced with what's left. We need a model where the author can resolve many precedence conflicts at once, in some general way, while still being able to adjust individual cases as desired.

The author's life would be simpler if he could declare precedence for entire groups of rules at a time. We already have rules coming in groups, right? The standard library is a group, each library extension is a group. If the author has organized his code into chapters, or sections, or files, then each one of those could be a group. Probably groups will be split into subgroups, too.
Of course, we may want to override a general precedence statement in particular cases. Maybe one rule in the group needs high priority, even though most of the group is low priority. Maybe you just need to tweak a specific case.
So the compiler will have to be able to figure out which precedence statements are exceptions. It will have to detect circular precedence. If it detects a conflict, it will have to ask for help in deciding which precedence statement takes precedence...
This is the point where you raise your hands -- good -- and ask, didn't you just say all that? Twenty minutes ago? Because the precedence mechanism I'm describing sounds exactly like the rule mechanism it's supposed to fix. Precedence is an atom; all those precedence statements are rules.

So I honestly don't know whether I have a workable system. Maybe the rule engine can manage itself, bootstrapping itself, with the complex cases resting on the simple cases. Or maybe it's all circular logic and it can't get off the ground.

A quick survey of other trouble spots:
Some properties are related. If X is the parent of Y, then Y is the child of X -- and it's also true that X is nonempty. We'd like to implement all of those computations as atoms, so that their behavior can be customized. But what does it mean to redefine the Child relation? Do you have to redefine Parent and Nonempty, too? That's fragile; keeping them in sync would be difficult. (Inform 7 avoids this by working at the high level of relations, instead of the low level of rules. That's clearly better for this case, but I'd like to find an approach that has the advantages of both.)
Some operations occur in several phases. An IF action typically has a "perform the work" phase and a "report what happened" phase. Do we set this up as one atom that does two things, or two atoms? The author probably wants to define them at the same time; writing one rule is conceptually easiest. And sometimes you want to override the whole thing with one rule. But then sometimes you want to change the displayed message, or change the underlying implementation, or maybe do the work silently. So we need to be able to treat the two phases separately.
You might try to write two rules with the same condition, so that they stay in sync automatically. But that's not always simple. The "perform" phase is changing the game state, so the condition might not be true any more by the time the "report" phase happens.
You might want to add a step to any atom -- something that happens before or after the original code. It makes sense to do this with some recursive rules, as shown above. You define a rule which does something and then calls the original rule. Or the other way around.
But again, what if you come back later and want to customize just one step of this multi-step process? Is there a model that makes sense?

I have ideas for dealing with each of these problems -- individually, for these short examples. Everything I've shown you has been a small example. The trouble is, I'm trying to find a solution that works for large examples. You can't use snippets that fit on a presentation slide to prove anything about a full-scale IF design system.
Inform 7 has been in development for six years, and in widespread use for three. It's still changing significantly with each release. That's how long it takes to hammer out design problems -- never mind the underlying plan that the design is built on.
If I'm lucky, I can adapt some of I7's experience to my own approach. But I won't know until I try putting together a complete IF library, and then writing a game in it. Kind of a daunting development plan.

References:
Notes on rule-based programming
A discussion on how such a language might work